Consumer concerns over if and how data is being used to train AI
Posted: June 17, 2024
You may have already seen the huge backlash in the news last week over Adobe customers cancelling their subscriptions left and right, furious that Adobe had updated its terms and conditions to supposedly use users’ content to train AI. Data privacy and how companies are using that data has become more and more concerning to consumers.
Recent updates to the terms and conditions by Adobe and Meta have sparked significant anxiety over how personal data is being used, particularly in training AI systems. These updates have inadvertently raised alarm bells among users who fear their data may be exploited without explicit opt-in consent.
Adobe’s terms & conditions update
Following an X (formerly Twitter) user’s post highlighting an update to Adobe’s terms of service, users across the world flooded social media with their concerns. Based on the screenshots of the terms of service (from @ThatGuyMike and @SamSantala), it would seem like Adobe could access anyone’s work at any time, and, presumably, use it to train its generative AI.
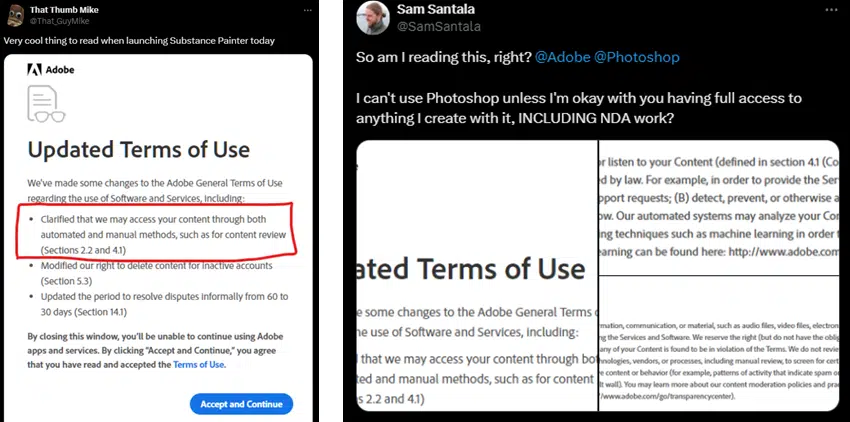
The vague language in the terms meant that users interpreted it to mean that the company was allowing itself free access to use people’s work to train Adobe’s generative AI models. This, however, was not the case. Scott Belsky, Adobe’s chief product officer, clarified that Adobe’s terms were similar to any software provider with cloud features, but did acknowledge that the wording was “unclear” and that “trust and transparency couldn’t be more crucial these days”.
In order to maintain trust with their customer base, Adobe will be rolling out new terms of service on June 18th to clarify these points and hopefully assuage any concerns, according to Adobe’s president of digital media, David Wadhwani.
“We have never trained generative AI on our customer’s content, we have never taken ownership of a customer’s work, and we have never allowed access to customer content beyond what’s legally required,” Wadhwani said to The Verge. “In retrospect, we should have modernized and clarified the terms of service sooner,” Wadhwani says. “And we should have more proactively narrowed the terms to match what we actually do, and better explained what our legal requirements are.”
Meta and training its AI via users’ social posts
In a similar vein, Meta recently released updated terms to say that it WILL start using everyone’s social media posts to start training its AI models – a feature which only users residing in the European Union can opt out of.
Previously, Meta had not included Europe in its AI training data, presumably because of the tighter legislation around data privacy. However, now it seems that it is pushing ahead.
“To properly serve our European communities, the models that power AI at Meta need to be trained on relevant information that reflects the diverse languages, geography and cultural references of the people in Europe who will use them,” Meta has said.
This is only from “public content”, Meta has clarified, and so will exclude users under 18 and private messages.
Meta took proactive steps in this process by sending billions of notifications to European users since May 22nd, offering them the chance to decline participation in AI training before the new rules take effect globally on June 26. According to Meta, any user can opt out without repercussions, ensuring their posts won’t be used to train AI models now or in the future.
This approach contrasts sharply with Meta’s policy outside Europe, where users do not have the option to opt out. While it is too late for users to prevent their data from being used in training Meta’s LLaMa 3 model, European users retain the exclusive ability to opt out of future AI training, a feature unavailable to Facebook and Instagram users elsewhere.
Despite Meta’s efforts, significant pushback in Europe seems inevitable. Meta’s intentions were signaled through a privacy policy update last week, which prompted the consumer privacy advocacy group noyb to file complaints across Europe. Noyb argues that data collection should allow for opt-in by default, not opt-out. Additionally, the permanence of data once integrated into large language models (LLMs) conflicts with the European Union’s Right to be Forgotten, likely fuelling further disputes.
Meta’s relationship with the EU is already strained, highlighted by recent EU investigations into issues such as child safety and misinformation. The introduction of AI training using user data is poised to deepen this tension. While Meta may feel confident in its position, the likelihood of legal and regulatory challenges from European authorities and privacy advocates remains high.
Following complaints from Ireland’s Data Protection Commission, Meta has paused plans to roll out AI tools in Europe as of 14th June. The company said it is “disappointed” by the Irish DPC “request” which came “on behalf of” European DPAs “to delay training our large language models (LLMs) using public content shared by adults on Facebook and Instagram.”
What are consumers really worried about?
The crux of the issue lies in the transparency and scope of data usage. Adobe and Meta, two giants in the tech industry, have made changes to their terms that allow for broader data utilization to enhance their AI capabilities. While these changes are intended to improve user experience and service efficiency, they have led to questions about the extent to which personal data is being mined and utilized.
For many consumers, the concern is not just about consent, but about understanding the specifics of data use. The technical jargon and complex legal language in these terms and conditions often leave users in the dark, unsure of what they have agreed to. This lack of clarity fuels fears about privacy invasion and data security.
Transparency and trust
A significant portion of the consumer anxiety stems from a perceived lack of transparency. Users feel that companies like Adobe and Meta need to do more to explain how data is collected, processed, and used. This includes providing clear, accessible information about data handling practices and the specific purposes for which data is utilized.
As global businesses are racing to keep up with user expectations on personalization and privacy, more of their customers are growing increasingly uneasy. In fact, 93% are concerned about the security of their personal information online.
Enhanced transparency of can help rebuild trust. By demystifying the data usage policies and offering users greater control over their personal information via consent management tools, companies can alleviate fears and deliver a more trusting relationship with their user base.
Regulatory and ethical considerations
The debate over data usage for AI training is not just a matter of corporate policy but also of regulatory and ethical importance. Governments and regulatory bodies are increasingly scrutinizing how tech companies handle personal data. Policies such as the General Data Protection Regulation (GDPR) in Europe set stringent standards for data privacy and user consent and have already come at odds with AI systems.
Ethical considerations also play a crucial role. Companies must balance innovation with respect for user privacy. This involves implementing data protection measures and ensuring that data usage aligns with both ethical guidelines and user expectations.
Moving forward
As Adobe and Meta continue to develop and deploy AI technologies, addressing consumer concerns about data usage will be critical. This includes not only adhering to regulatory standards but also fostering a culture of transparency and ethical responsibility.
For consumers, staying informed and proactive about data privacy is essential. Understanding the terms and conditions of the services they use, and taking advantage of privacy settings and controls, can help mitigate risks.
These updates to Adobe and Meta’s terms and conditions highlight a growing tension between technological advancement and data privacy. Navigating this requires effort from both companies and consumers to ensure that the benefits of AI do not come at the expense of personal privacy.


